
The careers site was never the whole story. Now it is barely the opening line. This is a comprehensive examination of how generative engines assemble the picture candidates see, why owning that narrative has become an infrastructure problem rather than a content one, and what enterprise and SME employers must build to remain legible to the machines that increasingly mediate the labor market.
Insights
- GEO optimizes for citation, not ranking. The goal is to be the source an AI engine draws from and attributes, not to appear at position one. The seminal KDD 2024 study found conventional SEO largely ineffective inside generative engines, while adding statistics, quotations, and citations lifted source visibility by up to 40%.
- Candidates already research employers through AI. Around 70% of job seekers use generative AI in their search (Indeed, 2025), and 40.7% reported using AI somewhere in their job search by mid-2025 (iHire).
- The summary is the destination. When a Google AI Overview appears, click-through to any organic result falls to roughly 8% (versus 15% without), and only about 1% of users click a citation inside the Overview (Pew Research Center, 2025).
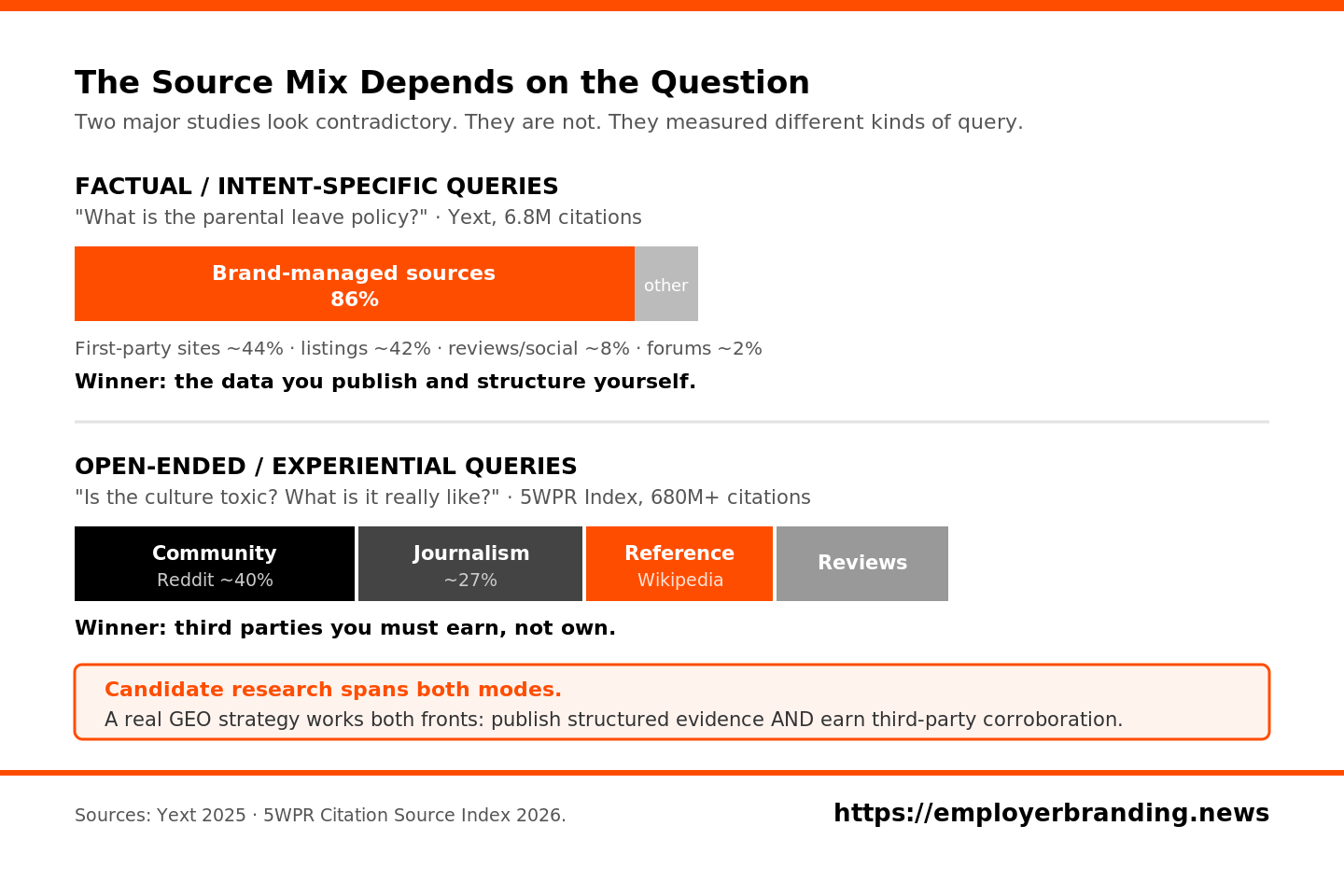
- The source mix is query-dependent. Brand-managed data wins on factual questions (Yext: 86% of citations); community, review and journalism sources win on experiential questions (5WPR Citation Source Index). Employer research spans both, so a serious strategy works on both fronts.
- GEO surfaces the credibility gap; it cannot conceal it. Because engines draw from owned content and reviews simultaneously, a weak EVP is exposed faster, not hidden.
Why this matters now
For roughly fifteen years, employer brand search strategy was a settled discipline. A candidate typed a question into Google, received a ranked list of blue links, and clicked through to a careers site, a Glassdoor profile, or a LinkedIn page. The employer's job was to rank well and to make the destination compelling once the candidate arrived. The model was legible, measurable and, crucially, it gave the employer a destination over which it had control.

Your employees know the truth. Does your EVP? At Fathom we measure the "Credibility Gap" between your promise and their reality.
That model is being dismantled in real time. Candidates increasingly pose their questions to generative engines such as ChatGPT, Google's AI Overviews and AI Mode, Perplexity, Gemini, Microsoft Copilot, and Claude, and receive a synthesized answer rather than a list of places to go. The answer is assembled on the fly from dozens of sources, weighted by signals the employer does not directly control, and delivered without the candidate ever arriving at a destination the employer owns. Pew Research Center's controlled study of real browsing behavior found that when a Google AI Overview is present, the click-through rate to any organic result falls to roughly 8%, against around 15% when no Overview appears, and that only about 1% of users click a citation link inside the Overview itself (Pew Research Center, 2025). The summary has become the destination.
The behavioral shift among candidates is no longer speculative. A 2025 Indeed survey reported that around 70% of job seekers now use generative AI to research companies, draft applications, and prepare for interviews (Indeed, 2025). iHire's June 2025 data found that 40.7% of candidates reported using AI somewhere in their job search, up from an expected 10.4% in early 2024 (iHire, 2025). Maria Christopoulos Katris, cofounder and CEO of Built In, framed the trajectory bluntly when her company launched a platform to measure employer reputation inside large language models: employers should “assume they are starting their search, they're identifying companies to work for, they're researching you, and they're making decisions, all without leaving an LLM” (HR Brew, 2026; Built In, 2025).
This article examines the mechanics of that shift in depth. It is concerned with three questions an enterprise talent leader and an SME founder alike now have to answer. First, what is the actual ecosystem of tools, platforms, and data sources that forms the picture a candidate sees? Second, what must an employer build and publish to own its Employer Value Proposition (EVP) narrative inside that ecosystem rather than ceding it to whatever data happens to exist? And third, how does an organization measure, monitor, and govern its representation in systems that are probabilistic, volatile, and occasionally wrong about it in ways that carry real reputational and legal risk?
Part 1: The academic foundation: what GEO actually is
The term Generative Engine Optimization was formalized by Aggarwal, Murahari, Rajpurohit, Kalyan, Narasimhan, and Deshpande in a paper first circulated in 2023 and presented at KDD 2024, the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Aggarwal et al., 2024). The paper is the field's seminal reference, and its findings remain the most rigorous empirical grounding available for everything that follows.
The researchers defined a generative engine as a system that satisfies a query by retrieving from multiple sources and synthesizing them into a single narrative answer using a large language model, rather than returning a ranked list. They then built GEO-bench, a benchmark of 10,000 queries across diverse domains, and tested whether the techniques content creators had spent two decades perfecting for traditional search actually worked in this new environment.
Their central finding has uncomfortable implications for any employer brand team still operating on an SEO mental model: conventional SEO techniques were largely ineffective at improving visibility inside generative responses. What worked instead were a distinct set of content interventions. Adding relevant statistics, incorporating credible quotations, and including citations to reliable sources improved a source's visibility within generative answers by up to 40% (Aggarwal et al., 2024). Stylistic improvements to fluency and readability produced gains of 15–30%. The effectiveness of each technique varied significantly by domain. An important caveat: there is no single universal recipe.
The practical translation for employer branding is precise. Generative engines reward content that is specific, attributable, and verifiable. A page asserting “we invest in our people” is, to a generative engine, almost worthless as a citation. A page stating “our internal mobility rate was 68% in 2025, and the median time to first promotion for engineers is 19 months” is extractable, quotable, and citable. This is the single most important conceptual shift the discipline requires: GEO does not optimize for ranking, it optimizes for citation, being the source an engine draws from and attributes, regardless of whether any traditional ranking position exists at all.
A note on terminology, because the field has generated a thicket of near-synonyms. GEO (Generative Engine Optimization) has academic provenance. AEO (Answer Engine Optimization) is used roughly interchangeably. LLMO, GSO, and AIO describe the same underlying practice. For employer brand purposes the distinctions are not material; this article uses GEO throughout.

Part 2: The ecosystem: who actually forms the picture
To own a narrative inside generative engines, an employer must first understand that the picture a candidate sees is not produced by any single system. It is assembled from a layered ecosystem, and each layer behaves differently.
The engines themselves
Five generative engines dominate candidate research, and they do not behave identically. This matters because an employer that optimizes only for one is optimizing for a fraction of the audience.
ChatGPT (OpenAI) draws heavily on encyclopedic and reference sources, with Wikipedia accounting for somewhere between a quarter and a half of its top citation share on factual queries, alongside Reddit, Forbes, and Business Insider (5WPR, 2026; Qwairy, 2025). Google AI Overviews and AI Mode sit on top of Google's index and knowledge graph, leaning on Google's own properties and high-authority third parties, with YouTube holding an outsized citation advantage inside Google's surfaces. Because Overviews appear in the search results most candidates still start from, they are arguably the highest-reach surface of all. Perplexity rewards primary sources and named authority, and shows little overlap with ChatGPT. One analysis found only around 11% of domains cited by both (Qwairy, 2025). Gemini (Google) and Microsoft Copilot inherit the tendencies of the index beneath them, and Claude (Anthropic) is increasingly used for research-style queries.
The strategically important fact is the divergence between these engines. Because they cite different sources, fixing your representation in one engine does not fix it everywhere. Visibility is engine-specific, so monitoring must be too.
The licensing layer: who paid to be in the corpus
There is a commercial layer beneath the citation patterns, and it is one most employer brand teams have never been shown. Generative engines do not only crawl the open web; they increasingly draw on content they have licensed, and a wave of deals signed since 2023 has quietly reshaped which publishers each engine can lean on. OpenAI alone has signed agreements with the Associated Press, Axel Springer (owner of Business Insider and Politico), the Financial Times, Condé Nast, Hearst, Vox Media, The Atlantic, Time, The Guardian, and News Corp, the last reported at up to $250 million over five years (Press Gazette, 2025; Variety, 2024). Google pays Reddit a reported $60 million a year for data access and runs a paid pilot with publishers including The Guardian and The Washington Post (Columbia Journalism Review, 2025; Press Gazette, 2025). Perplexity runs a revenue-share program rather than flat licensing, and Amazon, Anthropic, Microsoft, and Meta have each struck their own arrangements (Digiday, 2025; Axios, 2025).
The important nuance, and the one that keeps this honest, is that a licensing deal is not pay-to-rank. It grants an engine the right to train on and surface a publisher's content, and it increasingly comes with a structured attribution mechanism, the “source cards,” summaries, and outbound links that Anthropic, Perplexity, and the Guardian partnership all describe. What it does not do is mechanically guarantee that the engine will cite that publisher in answer to any particular query. The right word is eligibility, not endorsement. A licensed outlet sits inside the corpus an engine can confidently draw on and attribute; an unlicensed one may still be cited, but it competes from outside that trusted, permissioned set.
For employer brand and communications teams, this turns an abstract media-relations decision into a concrete targeting question. When you place an executive op-ed, a culture story, or a piece of original workforce research, the outlet's relationship with the major engines is now part of its value. A story in Business Insider is, by virtue of the Axel Springer deal, inside ChatGPT's licensed corpus; coverage carried by the Associated Press flows into Google's Gemini and AI Overviews; placement with a Perplexity revenue-share partner sits inside that engine's permissioned set. None of this guarantees a citation, but it stacks the structural odds. The table below maps the major publicly reported deals as of mid-2026 so teams can factor engine relationships into where they earn coverage. All financial terms are as reported by trade press and should be read as estimates rather than confirmed figures, since most agreements are governed by confidentiality.
Major publicly reported AI–publisher content deals as of mid-2026. Models differ: flat content licensing, usage-based revenue share, and open marketplaces. Dollar figures are as reported by trade press and should be read as estimates, not confirmed terms.
| # | AI platform | Publisher / partner | Model | Reported terms (source) |
|---|---|---|---|---|
| 1 | OpenAI (ChatGPT) | News Corp (WSJ, The Times, NY Post) | Content licensing | Up to $250M over 5 yrs (reported) · Press Gazette, 2025 |
| 2 | OpenAI (ChatGPT) | Axel Springer (Business Insider, Politico) | Content licensing | ~$13M/yr (reported) · Digiday, 2024 |
| 3 | OpenAI (ChatGPT) | Financial Times | Content licensing | $5–10M/yr (reported) · Press Gazette, 2025 |
| 4 | OpenAI (ChatGPT) | Dotdash Meredith | Licensing + ad tech | $16M+ (reported) · Digiday, 2024 |
| 5 | OpenAI (ChatGPT) | Associated Press | Content licensing | Undisclosed · Press Gazette, 2025 |
| 6 | OpenAI (ChatGPT) | Vox Media · The Atlantic · Time · Condé Nast · Hearst · The Guardian | Content licensing | Undisclosed · Variety, 2024 |
| 7 | OpenAI (ChatGPT) | Axios | Licensing + local-news funding | 3-yr partnership (reported) · OpenAI, 2025 |
| 8 | Google (Gemini, AI Overviews) | Data access / training | ~$60M/yr (reported) · Columbia Journalism Review, 2025 | |
| 9 | Google (Gemini, AI Overviews) | Associated Press | Real-time content | Undisclosed · Press Gazette, 2025 |
| 10 | Google (Gemini, AI Overviews) | Publisher pilot (Guardian, Washington Post, Times of India, Der Spiegel, El País, others) | Paid commercial pilot | Direct payments (terms undisclosed) · TechCrunch, 2025 |
| 11 | Perplexity | Publishers' Program / Comet Plus partners | Revenue share | $42.5M pool; publishers receive 80% (reported) · Digiday, 2025 |
| 12 | Amazon | The New York Times (incl. NYT Cooking, The Athletic) | Content licensing | $20–25M/yr (reported) · PYMNTS, 2025 |
| 13 | Anthropic (Claude) | The New York Times | Settlement + attribution | Confidential settlement (reported Dec 2025) · Digiday, 2025 |
| 14 | Microsoft (Copilot) | Publisher Content Marketplace (USA Today and others) | Marketplace (publishers set terms) | Per-publisher terms · Media Copilot, 2026 |
| 15 | Meta (Meta AI) | CNN, Fox News, Fox Sports, USA Today, Le Monde, People Inc, Daily Caller, Washington Examiner | Content licensing | Multi-year (terms undisclosed) · Axios, 2025 |

The source layer: a contested map
Two of the most rigorous recent attempts to map which sources generative engines cite reach strikingly different conclusions, and the tension between them is instructive rather than a reason to dismiss either.
The 5WPR AI Platform Citation Source Index 2026 synthesized more than 680 million individual citations across ChatGPT, Google AI Overviews, Perplexity, Gemini, and Claude, from six of the largest published citation studies between August 2024 and April 2026. Its headlines: Reddit is the single most-cited source across every major engine, at roughly 40% citation frequency; the top 15 domains absorb around 68% of the entire AI citation pipeline; journalism accounts for around 27% of all citations, rising to 49% on time-sensitive queries; and the system is volatile. ChatGPT's Reddit citation share reportedly fell from roughly 60% to 10% in six weeks in late 2025 after a single Google parameter change (5WPR, 2026).
Yext's study of 6.8 million citations across ChatGPT, Gemini, and Perplexity reached an apparently contradictory conclusion: 86% of AI citations came from sources brands already control: first-party websites (around 44%), structured listings (around 42%), and reviews and social (around 8%), with forums such as Reddit accounting for just 2% once location context and query intent were applied (Yext, 2025).
These findings are not actually incompatible, and reconciling them is the key analytical insight for employer brand teams. The 5WPR index measures open-ended, informational queries where the engine roams the web for the most authoritative or most discussed source, exactly the query a candidate asking “what is it really like to work at Company X” produces. Yext's study weighted location- and intent-specific commercial queries, where brand-managed structured data dominates. The source mix is query-dependent. Candidate employer research spans both modes: factual, structured questions (“what is the parental leave policy”) where brand-controlled data wins, and reputational, experiential questions (“is the culture toxic”) where community and review sources win. A serious GEO strategy must operate on both fronts simultaneously.
The employer-specific sources
Layered onto this general picture are the sources that specifically shape employer reputation:
- Review platforms. Glassdoor (now integrated with Indeed's review corpus), Indeed Company Pages, Comparably, and the anonymous community platform Blind. Generative models do not merely quote individual reviews; they statistically model patterns across the whole corpus to infer dimensions of employer quality and decide whether to describe a company positively, neutrally, or negatively (Single Grain, 2025).
- Professional and identity platforms. LinkedIn company pages, employee posts, and executive content.
- Encyclopedic and reference. Wikipedia above all, which carries outsized weight in ChatGPT and AI Overviews.
- Editorial and news. Trade press and business media the engines treat as high authority.
- Owned, structured careers content. The careers site, EVP pages, FAQ content, and machine-readable data the employer publishes about itself.
Katris's warning to HR Brew captures the consequence of neglecting this ecosystem: “If you haven't written a lot of positive, proactive content about your company in a controlled way on a third-party trust site, what you will see is that everything that shows up here is from reviews that have been posted across the digital footprint. And so, effectively, what you're saying is, ‘We're good with our former ex-employees describing our employer brand’” (HR Brew, 2026).
Part 3: Owning your narrative: communicating your EVP in the age of AI
If Part 2 establishes that the picture is assembled from a distributed ecosystem the employer only partly controls, Part 3 addresses the central question: what does an organization actually build and publish to make that assembled picture reflect its genuine EVP? This is not a campaign. It is the construction of a durable, machine-legible evidence base about the employment offer, distributed across the sources engines weight, and kept current. Five disciplines define it.

Discipline 1: Convert the EVP from claims into evidence
The foundational move is to translate every EVP pillar from aspiration into extractable, verifiable fact. Generative engines reward statistics, quotations, and citations (Aggarwal et al., 2024); an EVP expressed as values and adjectives gives them nothing to extract. If the pillar is career growth, publish the internal mobility rate, median time to promotion by function, and the proportion of senior roles filled internally. If it is work–life fit, publish the hybrid policy in concrete terms, the parental leave entitlement and its take-up rate. If it is pay, publish the pay philosophy, benchmarking approach, and pay-gap data. A verifiable number is citation fuel; a generic adjective is not.
A useful organizing scaffold is to structure this evidence around the dimensions candidates actually interrogate. Frameworks such as the Talent Gravity Standard's six drivers, namely Pay and Security, Role and Growth, Work-Life Fit, Culture and Connection, Purpose and Impact, and Equity and Identity, map closely onto the categories of employer question candidates pose to engines, serving the GEO purpose and the EVP-activation purpose at once (Talent Gravity Standard, 2026).
Discipline 2: Structure content for extraction
Generative engines extract answers to specific questions. Content architected around the questions candidates actually ask outperforms narrative culture pages. That means question-led page structures and FAQ schema (direct question-and-answer pairs); self-contained answers that make sense lifted out of the page, because that is precisely what an engine does to them; and a clear heading hierarchy with short paragraphs and discrete claims that aid retrieval.
Discipline 3: Make the organization machine-legible with structured data
This is where GEO becomes an infrastructure discipline rather than a content one, and where many employer brand teams are under-invested. Structured data, which is schema.org markup expressed as JSON-LD, encodes facts about the organization in a form engines and knowledge graphs ingest directly.
The evidence on schema's effect is genuinely nuanced and should be reported honestly. A December 2024 analysis found no simple correlation between sheer schema coverage and citation rates; minimal markup does not lift visibility, and sparsely populated schema can underperform having none (Search Engine Land, 2025). What the same body of work found is that attribute-rich schema, meaning fully populated Organization markup defining the canonical entity, plus FAQPage, JobPosting, and related types, was associated with substantially higher citation rates than generic markup (Averi, 2025). Schema is necessary infrastructure but only valuable when richly and accurately populated. The emerging llms.txt convention is worth implementing as low-cost future-proofing, while recognizing that crawler adoption remains limited (Search Engine Land, 2025).

A professional home for employer branding. The Institute of Employer Branding Professionals is being built and you can help shape it.
The Yext finding that 86% of AI citations on intent-specific queries come from brand-managed sources is the strongest available argument that this infrastructure layer is where employers retain the most direct control (Yext, 2025). The corollary is that consistency across those managed sources matters enormously: divergent or stale data across the careers site, listings, and LinkedIn teaches engines to distrust the entity.
Discipline 4: Build third-party corroboration
Because experiential and reputational queries draw on sources the employer does not own, owning the narrative requires presence beyond owned channels. This is the discipline most continuous with classical PR and earned media, now repurposed: placing genuine, specific employer stories in the editorial and trade outlets engines treat as authoritative; ensuring leadership is quoted in reputable publications; and recognizing that an accurate Wikipedia entry, where one legitimately exists, carries disproportionate weight. The consolidated evidence that journalism supplies around 27% of all AI citations, and nearly half on time-sensitive queries, quantifies why earned media remains a GEO asset rather than a legacy tactic (5WPR, 2026). When deciding where to earn that coverage, the publisher's AI-licensing relationships (see the licensing table in Part 2) are now part of the calculus: a story inside an engine's licensed corpus has a structural advantage as a future citation source.
Discipline 5: Manage review-platform health as a GEO asset
Review platforms are among the most heavily weighted sources for experiential employer queries, and engines model sentiment patterns across the whole corpus rather than reading single reviews. A declining Glassdoor rating, thin review volume, or a recurring negative theme will be reflected in the synthesized summary an engine produces. This reframes review management as a direct input to how AI describes the employer. The healthy posture is active and honest: encouraging genuine current-employee reviews to keep the corpus representative, responding substantively to criticism, and treating recurring negative themes as employment-reality problems to fix rather than reputation problems to spin.

One bad review shouldn't define you. ARC manages your employer reputation, from Glassdoor review removal to ambassador activation.
Part 4: Measurement and governance
A discipline that cannot be measured cannot be managed, and a representation system that can be wrong about you in defamatory ways cannot be left ungoverned.
Auditing: the zero-cost diagnostic
The most direct GEO diagnostic available to any team costs nothing. Prompt ChatGPT, Perplexity, Gemini, Copilot, and Google AI Overviews with the questions a candidate in each target talent pool would genuinely ask, such as “Is Company X a good place to work for data engineers?”, “What is Company X's culture like?”, “How does Company X handle career development and pay?”, then read the answers forensically across all engines. The output is a gap analysis: what is accurate, what is missing, what is wrong, and, most revealingly, what the engine has inferred in the absence of clear information. That inference is the danger zone: where there is no authoritative signal, engines fill the vacuum with plausible-sounding approximation drawn from whatever exists, frequently the oldest and most negative material.
Continuous monitoring: the tooling layer
A point-in-time audit is insufficient because the system is volatile. A dedicated category of AI-visibility monitoring tools has emerged to track brand and employer representation continuously across the major engines. Profound (which has raised around $155M and serves enterprise clients, with plans starting around $499/month) is positioned as the enterprise leader; Peec AI is positioned as a mid-market analytics challenger; and Otterly AI (from around $29/month) is the most accessible entry point (Surmado, 2026; Otterly, 2026). For employer-brand-specific monitoring, Built In's reputation platform is explicitly designed to measure and shape employer representation inside LLMs (Built In, 2025).
The metrics worth tracking are distinct from SEO metrics: share of citation (how often the employer is cited for relevant queries versus competitors), sentiment of the synthesized summary, accuracy of extractable claims, source mix, and consistency across engines. None of these is a ranking position; all are about presence and accuracy inside synthesized answers.
Governance and risk
Three governance risks deserve board-level attention, because GEO sits at the intersection of marketing, HR, legal, and data.
Accuracy and hallucination. Generative models predict plausible text rather than verify truth, and measured hallucination rates across leading models have been reported in wide ranges depending on task and methodology (National Law Review, 2025). For employer brand this manifests as confidently stated but false claims about pay, layoffs, leadership, or culture. The mitigation is partly offensive, flooding the ecosystem with authoritative, structured, consistent signal, and partly defensive, through continuous monitoring to detect and correct material errors early.
Defamation and legal exposure. The legal landscape is unsettled but moving. The first US defamation suit against an LLM producer, Walters v. OpenAI, resulted in summary judgment for OpenAI in the Superior Court of Gwinnett County, Georgia in May 2025, the court reasoning in part that users are warned outputs may be fabricated and that a reasonable reader would not treat the output as fact (Loeb & Loeb, 2025; Quinn Emanuel, 2025). Legal scholarship, notably Lidsky and Daves's “Inevitable Errors: Defamation by Hallucination in AI Reasoning Models” (2025), is actively debating where liability should sit. For an employer, the operational point is that there is currently no reliable legal remedy when an engine states something false and damaging about you as an employer; the practical defense is detection and correction-at-source, not litigation.
Employer branding now has a measurement standard. The Talent Gravity Standard is a six-driver framework for quantifying employer attractiveness and the gap between brand promise and employee experience.
Authenticity and the limits of optimization. The most important governance principle is also the most strategic. GEO cannot manufacture an EVP that does not exist. Because engines draw simultaneously from polished owned content and from reviews, employee posts, and news, they will surface divergence between promise and reality, the “credibility gap” between what an employer claims and what employees experience. An organization with a weak EVP and a deteriorating review profile will find aggressive content optimization surfaces the gap faster rather than concealing it. There is also a narrowing line between legitimate optimization (publishing accurate, structured, specific evidence) and manipulation (astroturfing reviews, generating fake positive content, a practice already visible in a reported 376% surge in AI-generated Glassdoor reviews, which platforms and engines are increasingly equipped to detect and discount) (techrSeries, 2025). Manipulation is both reputationally and increasingly technically self-defeating.
Part 5: Differentiated playbooks: enterprise and SME
The disciplines above apply universally, but resourcing realities differ sharply, and pretending otherwise produces unusable advice.
Enterprise employers typically have the opposite of an information vacuum: a large, sprawling, often inconsistent footprint across many sources, geographies, and legacy content. Their primary GEO problems are consistency and entity coherence, ensuring the same canonical facts appear across a global careers estate, hundreds of location listings, multiple Glassdoor and Indeed profiles, and a Wikipedia entry, so engines resolve them to one trustworthy entity. They have budget for enterprise monitoring, dedicated structured-data engineering, and an earned-media function. Their risk is organizational: GEO requires HR, comms, brand, legal, and web engineering to coordinate, and in large organizations those functions are siloed. The enterprise priority is governance and consistency at scale.
SME employers face the inverse problem: a thin footprint that engines fill with inference or a handful of unrepresentative reviews. A single negative Glassdoor review carries far more weight when there are only five of them. SMEs cannot fund enterprise tooling or a PR retainer, but they have advantages: agility, a coherent single culture that is easy to articulate honestly, and the ability to implement structured data and question-led content quickly and cheaply. The SME priority is foundational presence: a richly populated Organization and FAQPage schema, a genuinely specific and honest EVP evidence page, an actively maintained Glassdoor and LinkedIn presence to build review volume, and a low-cost monitoring tool to run a monthly audit. For an SME, the marginal return on simply existing legibly in the ecosystem is enormous, because the alternative is being described entirely by inference.
Closing reflection
The shift to generative engines does not change what good employer branding has always rewarded. It changes the speed at which the reward and the penalty arrive, and the form in which the work must be expressed, shifting from persuasive narrative aimed at humans to structured, specific, corroborated evidence aimed at machines that humans now trust to summarize the world for them.
The organizations that will be well represented in AI employer summaries in 2027 and beyond are not those that optimize most aggressively as a technical exercise. They are those that have the most specific, credible, consistently communicated, and independently corroborated employer story, and that have built the machine-legible infrastructure to make that story findable, extractable, and current across the distributed ecosystem engines draw from. GEO rewards substance and punishes its absence, faster than search ever did. The careers site is no longer the whole story, but the truth of the employment experience, expressed in evidence, is more decisive than it has ever been.
Takeaways
What is GEO in employer branding?
Generative Engine Optimization (GEO) is the practice of structuring employer brand content and managing external reputation signals so that AI tools such as ChatGPT, Perplexity, Google AI Overviews, Gemini, and Claude cite an organization accurately when candidates ask employer-related questions. Unlike traditional SEO, the goal is to be cited inside an AI-generated answer rather than to rank in a list of results.
How is GEO different from SEO?
Traditional SEO optimizes for ranking, meaning appearing at the top of a results page. GEO optimizes for citation, being the source an AI draws from when constructing a synthesized answer. The seminal KDD 2024 research found conventional SEO techniques largely ineffective inside generative engines, while adding statistics, quotations, and citations boosted visibility by up to 40%.
Why does GEO matter for employer brand teams?
Candidates increasingly research employers through AI before applying. Around 70% of job seekers use generative AI in their search (Indeed, 2025), and 40.7% reported using AI somewhere in their job search by mid-2025 (iHire). AI tools build employer summaries from external sources including review platforms, media coverage, and structured careers content. Organizations that do not manage these signals find the AI summary is assembled from whatever data happens to exist.
What employer content performs best in generative engine searches?
Content that answers specific candidate questions directly, makes claims that are specific and verifiable rather than aspirational, is structured with clear headings and FAQ-style question-and-answer formats, and is distributed across third-party sources engines treat as authoritative. Generic culture copy performs poorly; specific data on internal mobility, pay philosophy, working arrangements, and career pathways performs well.
How do you audit your employer brand's AI presence?
Prompt ChatGPT, Perplexity, Gemini, Copilot, and Google AI Overviews with the questions a candidate in each target talent pool would ask about working at your organization. Note what is accurate, what is missing, what is inaccurate, and what the AI has inferred in the absence of clear information. That gap analysis is the starting point for a GEO content strategy.
What role do review platforms play in GEO?
Review platforms such as Glassdoor, Indeed, and Blind are among the most heavily weighted sources in AI employer summaries on experiential questions. Engines model sentiment patterns across the whole review corpus rather than reading single reviews, so rating, volume, sentiment themes, and response quality all shape what AI tools say about an employer. Review-platform health is a GEO asset, not only a candidate-experience consideration.
Is GEO a replacement for traditional employer brand strategy?
No. GEO rewards organizations that have done the underlying work: a researched EVP, an honest articulation of the employment reality, and a review profile that reflects genuine experience. For those organizations, GEO is primarily a distribution challenge. For organizations with a significant gap between promise and lived experience, optimizing for GEO surfaces the gap rather than concealing it.
References
All statistics and quotations in this article are drawn from the sources below. Where a primary survey was reported via a secondary aggregator, the publisher column notes this.
| # | Source | Publisher | Used for |
|---|---|---|---|
| 1 | GEO: Generative Engine Optimization | Aggarwal et al., KDD 2024 | Seminal GEO paper; statistics/quotations/citations lift visibility up to 40%; conventional SEO largely ineffective |
| 2 | Schema Markup for AI Citations: Technical Implementation Guide | Averi, 2025 | Attribute-rich schema vs generic markup; JSON-LD citation-rate evidence |
| 3 | Built In Launches Platform to Measure Employer Reputation in LLMs | Built In / PR Newswire, 2025 | Katris quote; employer reputation measured inside LLMs; reputation platform |
| 4 | The AI Platform Citation Source Index 2026 | Everything-PR / 5WPR, 2026 | 680M+ citations; Reddit ~40%; top 15 domains ~68%; journalism ~27%; volatility |
| 5 | AI is changing how people look for jobs, forcing recruiters to keep up | HR Brew / McGlauflin, 2026 | Katris on candidates starting and stopping search in LLMs; GEO for talent |
| 6 | AI in the Job Search Survey, June 2025 | iHire, 2025 | 40.7% of candidates used AI in job search by mid-2025 (vs 10.4% expected early 2024) |
| 7 | Job seeker use of generative AI in company research | Indeed, 2025 | ~70% of job seekers use generative AI to research companies and applications |
| 8 | Inevitable Errors: Defamation by Hallucination in AI Reasoning Models | Lidsky & Daves, 2025 | Legal scholarship on where liability sits for AI hallucination/defamation |
| 9 | Walters v. OpenAI, L.L.C. | Loeb & Loeb, 2025 | First US LLM defamation suit; summary judgment for OpenAI (Gwinnett County, May 2025) |
| 10 | AI Hallucinations Are Creating Real-World Risks for Businesses | National Law Review, 2025 | Hallucination as a business/reputation risk; accuracy and verification |
| 11 | 10 Best AI Search Monitoring and LLM Monitoring Solutions | Otterly AI, 2026 | AI-visibility monitoring tool category and entry-level pricing |
| 12 | Google users' click-through behavior with AI Overviews present | Pew Research Center, 2025 | CTR ~8% with AI Overview vs ~15% without; ~1% click citations inside the Overview |
| 13 | Perplexity vs ChatGPT: AI Citation Behavior Study (Q3 2025) | Qwairy, 2025 | Engine-by-engine citation divergence; ~11% domain overlap ChatGPT/Perplexity |
| 14 | Client Alert: Defamation in the AI Era | Quinn Emanuel, 2025 | Legal analysis of AI defamation exposure and Walters reasoning |
| 15 | How schema markup fits into AI search, without the hype | Search Engine Land, 2025 | Nuanced schema evidence; llms.txt adoption; what actually moves citation |
| 16 | How LLMs Choose Top Companies to Work For | Single Grain, 2025 | How engines model review-corpus sentiment to describe employers |
| 17 | Best AI Visibility Tools 2026: Profound vs Peec vs Otterly | Surmado, 2026 | Enterprise vs mid-market vs accessible monitoring tooling and pricing |
| 18 | Talent Gravity Standard: open framework documentation | Fathom Data Labs, 2026 | Six-driver model mapping the dimensions candidates query engines about |
| 19 | AI-Generated Reviews on Glassdoor Surge by 376.3% | techrSeries, 2025 | Manipulation/astroturfing risk; platforms detecting fake positive reviews |
| 20 | Yext Research: 86% of AI Citations Come from Brand-Managed Sources | Yext, 2025 | 6.8M citations; 86% brand-managed on intent queries; first-party/listings/reviews split |
| 21 | Who is suing, who is signing? News publisher AI deals and lawsuits | Press Gazette, 2025 | Running tracker of AI–publisher licensing deals and litigation across platforms |
| 22 | 2024 in review: publisher and AI company deals timeline | Digiday, 2024 | Axel Springer ~$13M/yr, Dotdash Meredith, and other OpenAI deal terms |
| 23 | OpenAI inks licensing deals to bring Vox Media, The Atlantic content to ChatGPT | Variety, 2024 | Vox Media and The Atlantic OpenAI licensing announcements |
| 24 | Partnering with Axios expands OpenAI's work with the news industry | OpenAI, 2025 | Axios 3-year partnership; attributed summaries, quotes and links in ChatGPT |
| 25 | Reddit is winning the AI game | Columbia Journalism Review, 2025 | Google's reported ~$60M/yr Reddit data-access deal; licensing dynamics |
| 26 | Google announces first AI deals with publishers | Press Gazette, 2025 | Associated Press real-time content for Gemini; Google publisher pilot |
| 27 | Google tests AI-powered article overviews for select publications | TechCrunch, 2025 | Google paid commercial pilot with Guardian, Washington Post and others |
| 28 | How Perplexity's new revenue model works | Digiday, 2025 | Perplexity Comet Plus revenue share; $42.5M pool, publishers receive 80% |
| 29 | Amazon paying New York Times $25 million for AI licensing | PYMNTS, 2025 | Amazon NYT deal ($20–25M/yr) covering NYT, Cooking, The Athletic |
| 30 | Amazon and the NYT AI deal signals a new wave of publisher partnerships | Digiday, 2025 | Context on Anthropic–NYT settlement and attribution source cards |
| 31 | Microsoft launches Publisher Content Marketplace for AI licensing | Media Copilot, 2026 | Microsoft marketplace model; publishers set terms; Copilot first buyer |
| 32 | Meta strikes AI deals with news publishers | Axios, 2025 | Meta AI licensing with CNN, Fox News, USA Today, Le Monde and others |